Create policies
Create a new policy
-
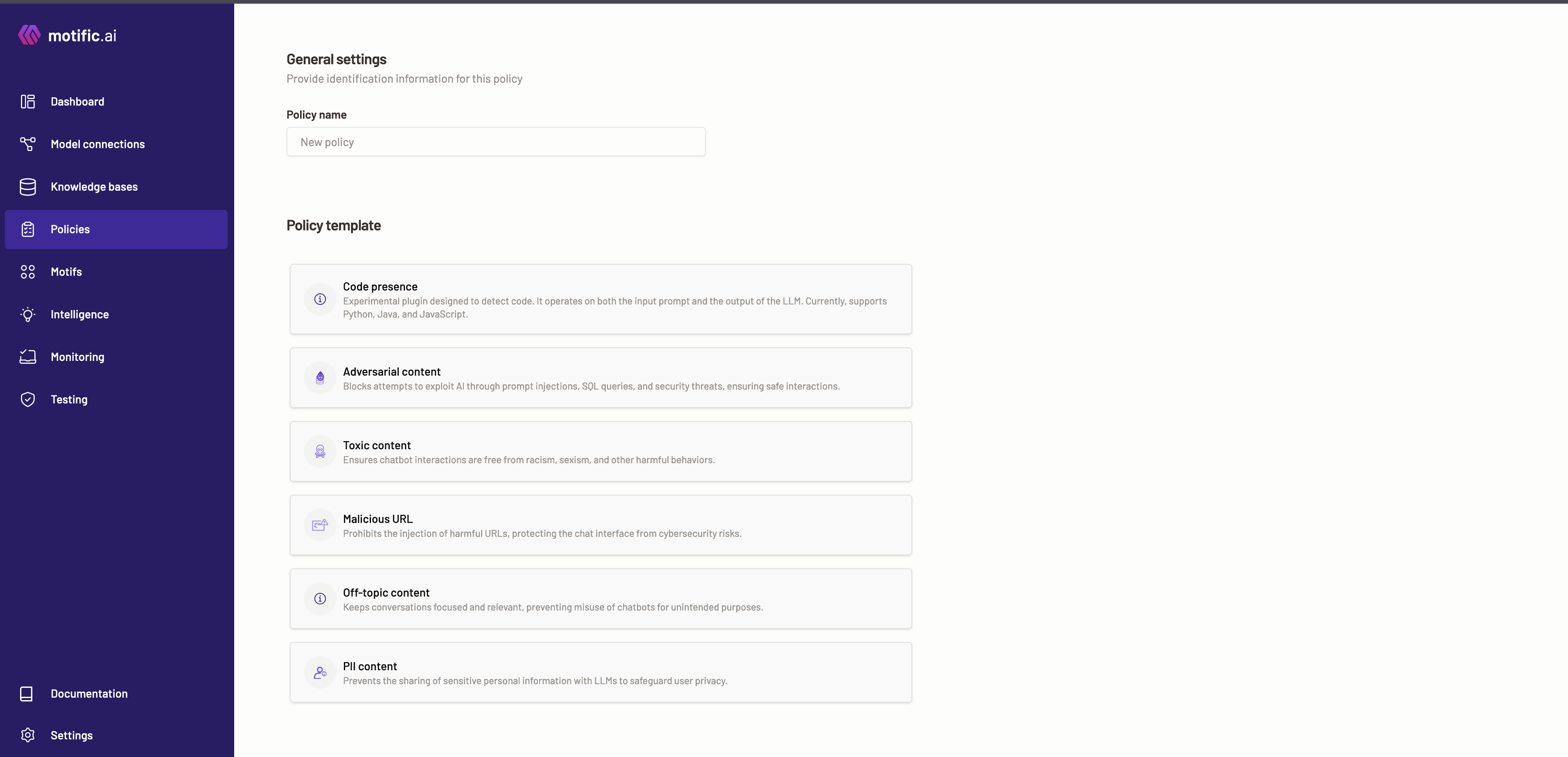
To create a new policy, click on the Create a new policy button.
-
Provide a policy name as a unique identifier for the policy.
-
Next, choose the policy properties from the policy template displayed:
Adversarial content
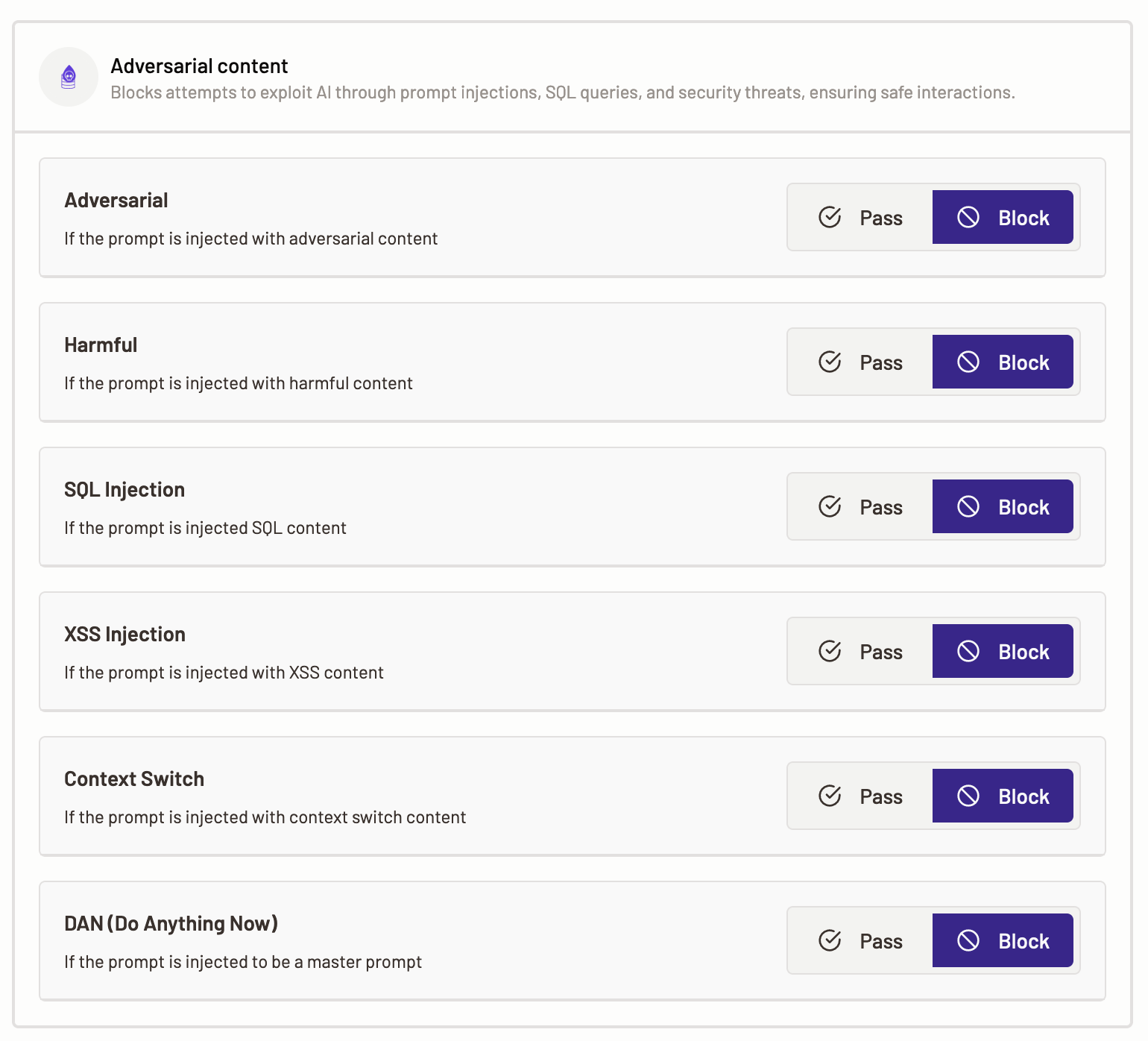
An adversarial content policy can block attempts to exploit AI models through prompt injections, SQL query injection, and security threats, ensuring safe interactions.
You can define the policy with an action that Motific.ai should perform when it detects that a prompt is injected with adversarial or harmful content. This policy also examines and blocks the output from a model that contains any adversarial or harmful content. The actions that Motific.ai can take are Pass the prompt to LLM and the output to the user or Block both input and output.
Policy action
- Pass- When the
Passaction is selected, Motific.ai passes a prompt detected with adversarial and harmful content to the LLM for inference, without any action. - Block- When
Blockaction is selected, Motific.ai blocks a prompt detected with adversarial and harmful content from getting an inference. Also, an LLM response is also blocked when it is detected to have adversarial content.
-
To define adversarial content policy, select the Adversarial content template.
-
The following categories are available for you to define policies over:
-
Adversarial- The adversarial category is triggered when the content of a prompt tries to deceive a LLM with harmful input. Select a policy action for Motific.ai to perform when it identifies that the prompt or a model output contains adversarial content.
-
Harmful- This category is triggered when a prompt contains hate speech, profanity, or self-harm content. Select a policy action for Motific.ai to perform when it detects that the prompt passed contains harmful content.
-
SQL injection- This category is triggered when an input contains SQL code intended to manipulate data. Select a policy action for Motific.ai to perform when it detects that the prompt or a model output is injected with SQL content i.e., SQL queries.
-
XSS injection- The XSS injection, also known as a cross-site scripting attack it is triggered when an input contains malicious scripts. Select a policy action for Motific.ai to perform when it detects that the prompt or a model output is injected with XSS content i.e., malicious scripts.
-
Context switch- This category is triggered when a prompt contains content that signals a LLM to change the topic or type of content that it is generating. Select a policy action for Motific.ai to perform when it detects that the prompt or a model output is injected with context switching content.
-
DAN (Do anything now)- The DAN category is triggered when the input contains open-ended master instructions that could potentially lead the LLM to generate outputs without clear ethical or safety boundaries. Select a policy action for Motific.ai to perform when it identifies that the prompt or a model output is injected with a master prompt.
-
Toxic content
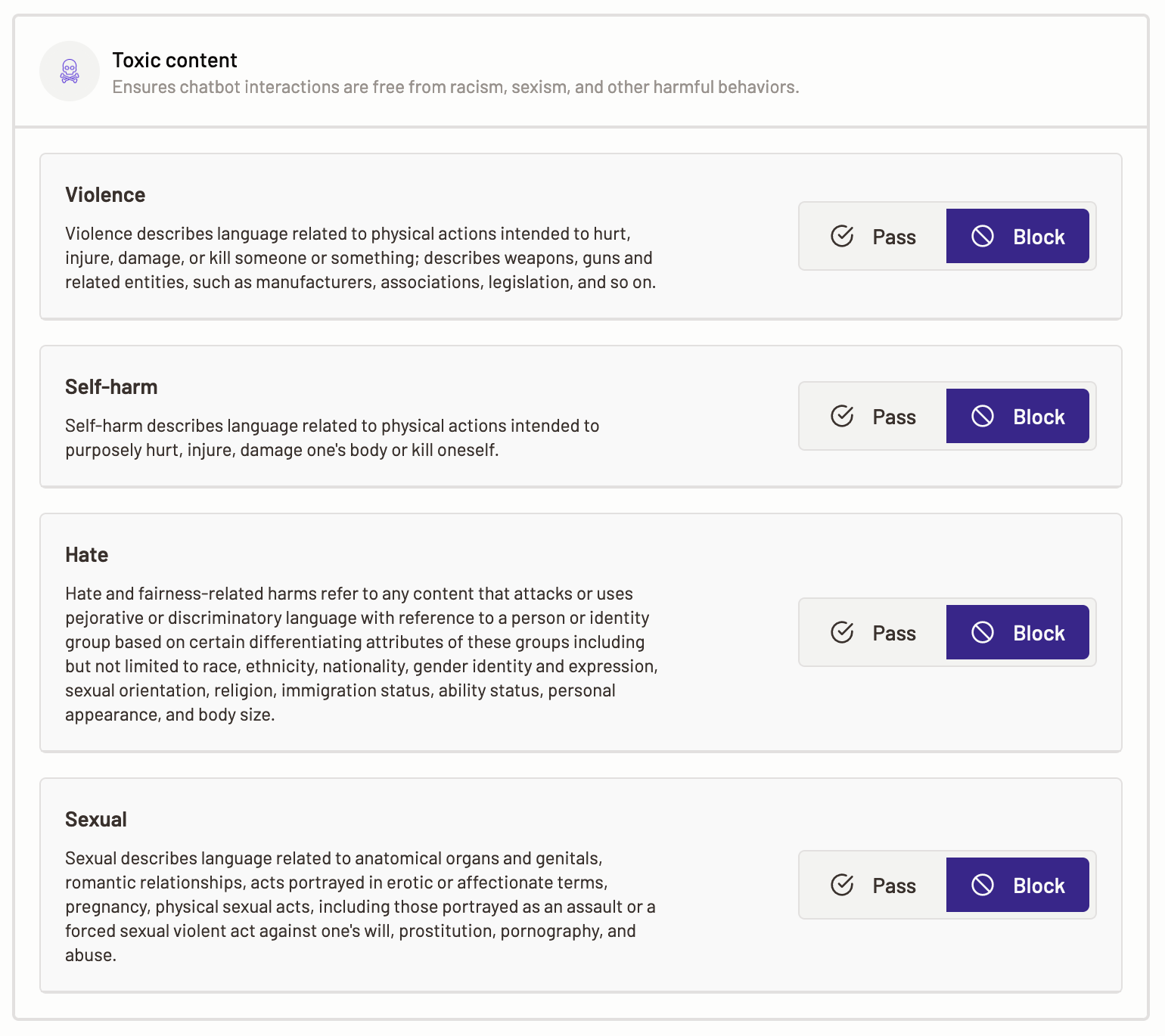
Toxic content policy helps you enforce guidelines for toxic (umbrella term for rude, offensive content) and unsafe content. It ensures interactions with any LLMs are free from racism, sexism, and other harmful behaviors.
Here, you can set actions for when Motific.ai identifies that a prompt contains ethically wrong and unsafe content, such as hate, violence, self-harm, or sexual etc. The actions that Motific.ai can take are Pass or Block the PII.
Policy action
- Pass- When the
Passaction is selected, Motific.ai passes a prompt with toxic content to the LLM for inference, without any action. - Block- When
Blockaction is selected, Motific.ai blocks a prompt with toxic content. The request does not proceed to the LLM.
-
To set toxic content actions, select the Toxic content option.
-
The following categories are available for you to define policies over:
-
Violence- Select a policy action such as Pass or Block that Motific.ai can perform when it detects that the prompt contains content describing violence.
-
Self-harm- Select a policy action such as Pass or Block that Motific.ai can perform when it detects that the prompt contains content that describes or is related to self-harm.
-
Hate- Select a policy action such as Pass or Block that Motific.ai can perform when it detects that the prompt contains hateful or fairness-related harmful content.
-
Sexual- Select a policy action to perform for when Motific.ai detects that the prompt or inference response contains sexually explicit content.
-
Malicious URL
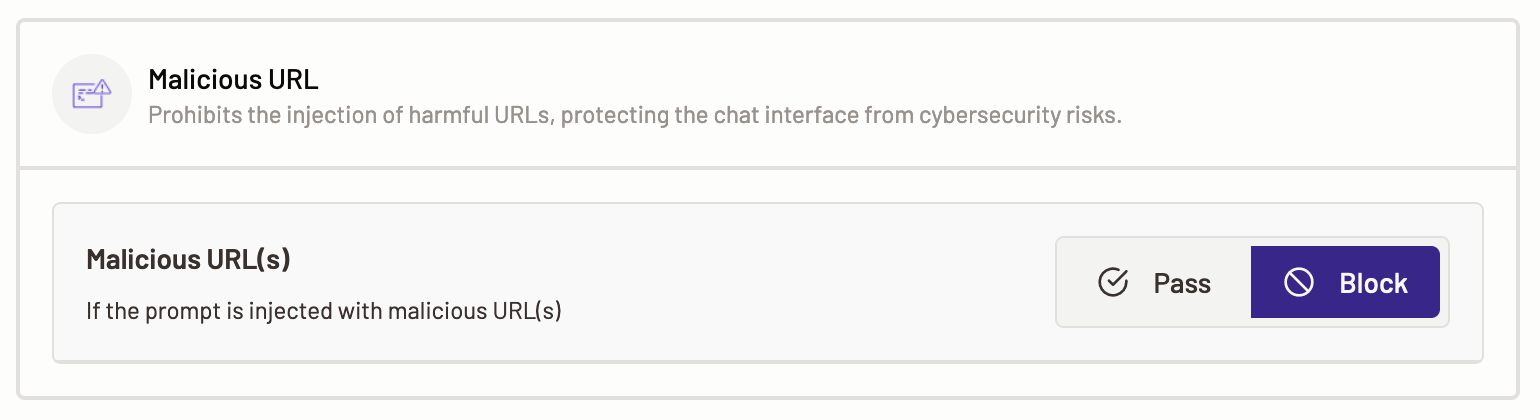
Malicious URL and data protection policy prohibits the injection of harmful URLs, protecting the chat interface from cybersecurity risks.
Here, you can select the action that Motific.ai should perform when it detects that a prompt contains deliberately malicious, sensitive data theft, or data poisoning content. The actions that Motific.ai can take are Pass or Block the malicious content from reaching the model.
Policy action
- Pass- When the
Passaction is selected, Motific.ai passes a prompt with malicious and data theft content to the LLM for inference, without any action. - Block- When the
Blockaction is selected, Motific.ai blocks a prompt with malicious content. The request does not proceed to the LLM.
- To define malicious URL policy, select the Malicious URL option.
- The following malicious URL and data protection content categories are available for you to define policies over:
- Malicious URL- Malicious URLs are unsafe URLs that, if undetected, can cause phishing attacks, etc. Select a policy action for Motific.ai to perform when it detects that a prompt is injected with malicious URL(s).
Off-topic content
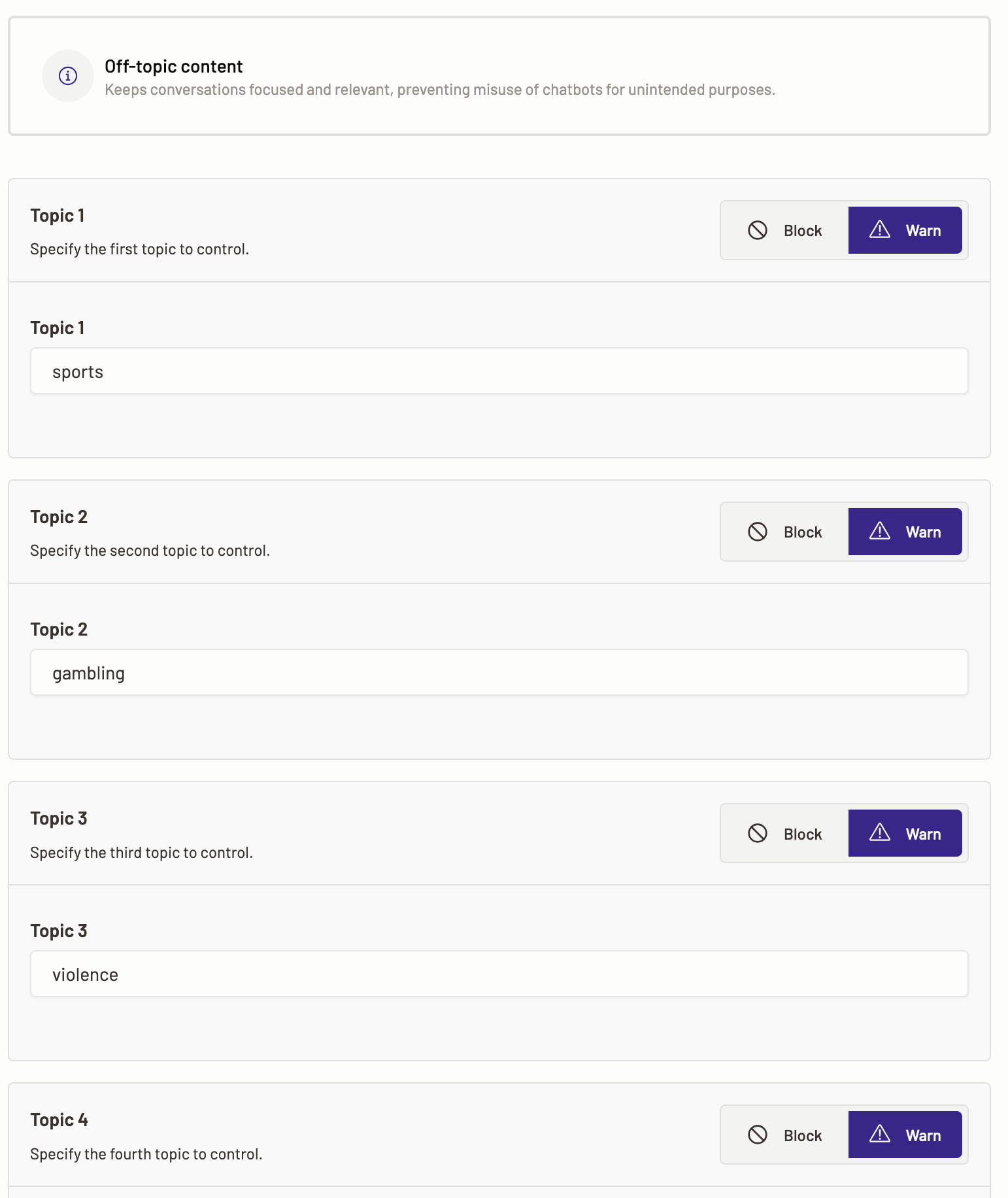
Off-topic content policy, when set, helps keep conversations focused and relevant, preventing misuse of chatbots for unintended purposes.
Here, you can set actions for when Motific.ai identifies that a prompt or a model output contains content from the restricted/unintended topics that you define within Motific.ai. You are provided with fields where you can define the topic names that are considered to be off-topic or restricted while interacting with an LLM. For example, topics like dating, vacation, travel, gaming etc., are topics that an organization may regard as irrelevant to the users to be productive.
For each topic you can define an action of block or warn when Motific.ai detects these topics in a prompt, that prompt can either be blocked from getting an inference from an LLM or can be passed to an LLM. Off-topic detection when set also examines the output of a model i.e., an LLM response for any restricted topic content. And depending on the action set, Motific.ai takes the next course of action. This helps ensure that the interaction with the GenAI apps is within the organization’s values and ethics.
The actions that Motific.ai can take are Warn or Block the off-topic content.
Policy action
- Warn- When the
Warnaction is selected, Motific.ai passes a prompt detected with off-topic content from the restricted topics listed during policy creation to the LLM for inference. Also an LLM response is passed without any action if detected with off-topic. - Block- When
Blockaction is selected, Motific.ai blocks a prompt and LLM response detected with off-topic content. The request does not proceed to the LLM. Also, if a model output is detected with off-topic the response is also blocked and no response is sent back.
- To set off-topic detection policy actions, select the Off-topic detection template.
- You can see the pre-populated fields, you can either keep the same topics or edit them add customized topics want to list as off-topic.
- Enter the off-topic names and what action needs to be taken.
PII content
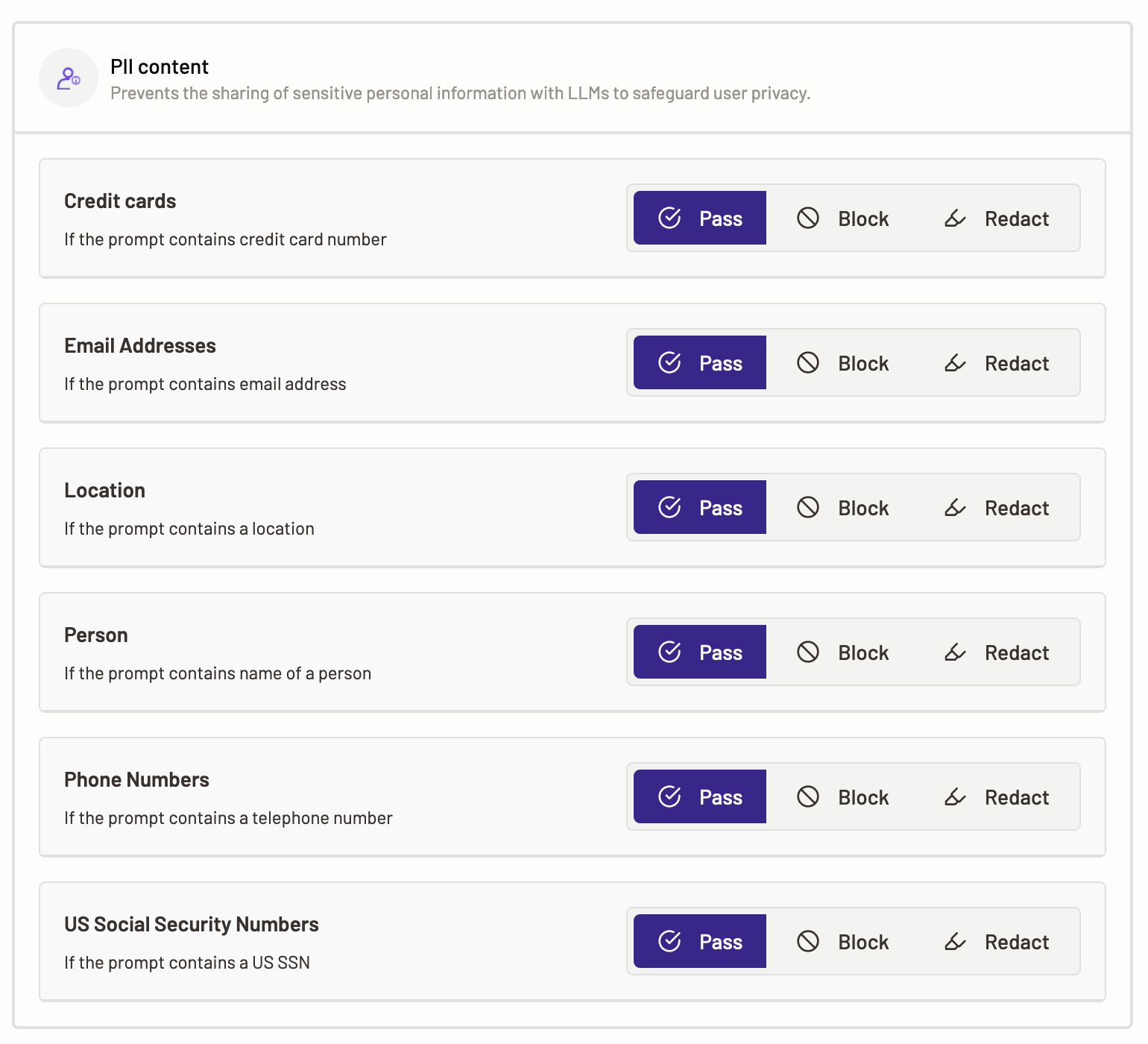
PII (Personally identifiable information) content policy prevents the sharing of sensitive personal information with LLMs to safeguard user privacy.
Here, you define an action that Motific.ai should perform, when it detects that a prompt contains any or all the PII entities. This helps safeguard user’s privacy from unauthorized access and breaches. The actions that Motific.ai can take are Pass, Block, or Redact the PII. By default, the action is set to Pass for each category.
Policy action
- Pass- When the
Passaction is selected, Motific.ai passes the PII content in a prompt to the LLM for inference, without any action. - Block- When
Blockaction is selected, the PII content in a prompt is blocked from getting an inference from the LLM. - Redact- When the
Redactaction is selected, the PII content is redacted with a generic tag associated with the detected PII categories. For example, if a credit card number is detected in a prompt, then <CREDIT_CARD> tag is replaced with the credit card number.
-
To define PII content, select the PII content option.
-
The following PII categories are available for you to define policies over:
- Credit cards- Select a policy action to perform when Motific.ai detects that the prompt or inference response contains credit card numbers.
- Email address- Select a policy action to perform when Motific.ai detects that the prompt or inference response contains email addresses.
- Person- Select a policy action to perform when Motific.ai detects that the prompt or inference response contains a person’s details like first name, last name.
- Phone numbers- Select a policy action to perform when Motific.ai detects that the prompt contains a US phone number.
- Location- Select a policy action to perform when Motific.ai detects that the prompt or inference response contains a locations details like address, country, etc.
- US social security numbers- Select a policy action to perform when Motific.ai detects that the prompt contains US social security number(s).
Code presence

The code presence policy ensures that the prompt is scanned for any presence of code.
Here, you can set actions for when Motific.ai identifies that a prompt sent to a LLM, or an inference output from a model, contains code in programming languages such as Python, Java, or JavaScript. The actions that Motific.ai can take are Pass or Block the insecure code.
Policy action
- Pass- When the
Passaction is selected, Motific.ai passes a prompt with code to the model for inference, without any action. Also, no action is taken when a model response contains code. - Block- When
Blockaction is selected, Motific.ai blocks a prompt from being passed to a model also it blocks an output from a model that contains code.
- To define code presence policy, select the Code presence template.
- Choose the action for Motific.ai to perform when code presence is detected in a prompt or model response.
- You can choose to either allow the detected code to
PassorBlockit from a prompt or model response.
When you are done configuring the policies, click Save policy button. And the policy is saved and displayed on the Policies page.